
The Case for
Compact AI
Tim Menzies · Posted Jul 10, 2025
Published as “The Case for Compact AI,” Communications of the ACM 68(9), Sep 2025, pp. 6–7. doi:10.1145/3746057[0]
“ State-of-the-art results come from smarter questioning, not planetary-scale computation. ”
Reading CACM's March 2025 issue, it struck me how many articles assume Large Language Models are the inevitable and best future path for AI. This post invites you to question that assumption.
To be clear: I use LLMs, a lot — for solo and tactical tasks such as condensing my arguments into short prose. But for strategic tasks that might be critiqued externally, I need other tools: faster, simpler, and whose reasoning can be explained and audited. I do not want to replace LLMs. I want to ensure we are also supporting and exploring alternatives.
The 5% Problem
In software engineering, very few researchers explore alternatives to LLMs. A recent systematic review found only 5% of hundreds of SE LLM papers considered alternatives[1]. A major methodological mistake that ignores simpler and faster methods. For instance, UCL researchers found SVM+TF-IDF methods vastly outperformed standard "Big AI" for effort estimation — 100 times faster, with greater accuracy[2].
Funneling
One reason for asking "if not LLM, then what?" is that software often exhibits funneling: despite internal complexity, behavior converges to few outcomes, enabling simpler reasoning[3],[4]. Funneling explains how my "BareLogic"[5] active learner can build models using very little data for (e.g.) 63 SE multi-objective optimization tasks from the MOOT repository[6]. These tasks cover software process decisions, configuration tuning, and learner tuning for analytics — better advice for project managers, better control of options, sharper local analytics.
BareLogic
MOOT includes 100,000s of examples with up to a thousand settings. Each example labelled with up to five effects. Obtaining labels is slow, expensive, error-prone. Hence the task of active learners like BareLogic: find the best example(s), after requesting the least number of labels[7].
BareLogic labels N=4 random examples, then:
- Scores and sorts labeled examples by "distance to heaven" (heaven = ideal target, e.g. weight=0, mpg=max).
- Splits the sort into √N best and N−√N rest.
- Trains a two-class Bayes classifier on best and rest.
- Finds unlabeled example X most likely best via
argmaxX ( log like(best | X) − log like(rest | X) ). - Labels X, increments N.
- If N < Stop, go to step 1. Else return top-ranked labeled example and a regression tree built from the N labeled examples.
Written for teaching as a simple demonstrator. But consistent with funneling, this quick-and-dirty tool achieves near optimal results using a handful of labels.
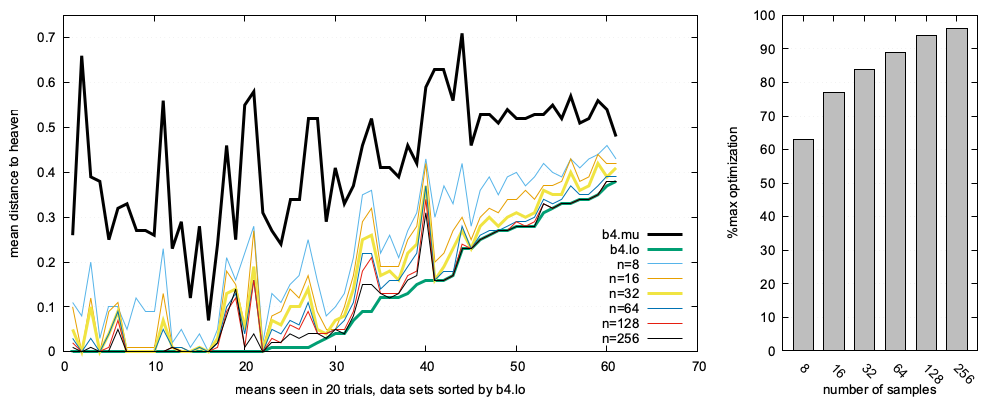
Across 63 tasks: eight labels yielded 62% of optimal; 16 reached nearly 80%; 32 approached 90%; 64 barely improved on 32.
Why It Wins
State-of-the-art with smarter questioning, not planetary-scale compute. Active learning addresses common LLM concerns:
energy & hardware — no billions of parameters, no specialized silicon.
testability & reproducibility — fast Bayesian active learning, fully repeatable.
explainability — results explained via small labeled sets (e.g. N=32) and tiny regression trees. Humans can guide reasoning whenever a label is required.
Weight Loss for AI
I am not the only one proposing weight loss for AI. LLM distillation — shrinking huge models for specific purposes[8] — already shows giant models are not always necessary. Active learning pushes the idea further: leaner, smarter modeling achieves great results.
why not try something smaller and faster?
References
- Menzies, T. The Case for Compact AI. Commun. ACM 68(9), Sep 2025, 6–7. doi:10.1145/3746057
- Hou, X. et al. Large Language Models for SE: A Systematic Literature Review. TOSEM 33, 8 (Sept 2024).
- Tawosi, V., Moussa, R., Sarro, F. Agile Effort Estimation: Have We Solved the Problem Yet? IEEE Trans SE 49, 4 (2023), 2677–2697.
- Menzies, T., Owen, D., Richardson, J. The Strangest Thing About Software. Computer 40, 1 (2007), 54–60.
- Lustosa, A., Menzies, T. Less Noise, More Signal: DRR for Better Optimizations of SE Tasks. arXiv:2503.21086
- Menzies, T. BareLogic Python Source Code. github.com/timm/barelogic
- Menzies, T. MOOT—Many multi-objective optimization tests. github.com/timm/moot
- Settles, B. Active learning literature survey. Tech. Rep. 1648, U. Wisconsin-Madison Dept of CS, 2009.
- Zeming, L. et al. Survey on Knowledge Distillation for Large Language Models. ACM Trans. Int. Systems & Technology (2024).
150 words of css
designed.2.last